






Especificaciones técnicas de Powerhouse
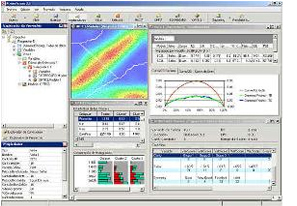 Powerhouse carga los datos en memoria lo que le permite ejecutar los algoritmos en forma rápida y eficiente.
Powerhouse carga los datos en memoria lo que le permite ejecutar los algoritmos en forma rápida y eficiente.
Carga los datos directamente en formato texto o a través de ODBC en cualquier formato.
Trabaja con datos hasta 10.000 variables y sin límites en la cantidad de filas.
Separa los datos en forma automática en Desarrollo (Training Set) y Prueba (Test Set).
Los datos de prueba son utilizados solamente para evaluar el modelo a pedido del usuario ya que el modelo es desarrollado enteramente con los datos de desarrollo.
Genera y carga una especificación de los datos si es necesario (metadata)
Definición de Nulos (por ejemplo, se puede definir que un nulo es un vacío o un label cualquiera)
Reemplazo automático de Nulos tanto en datos de desarrollo como en datos de prueba, en forma separada
Trabaja con variables de distintos tipos:
1. Variables numéricas (números enteros o decimales)
2. Variables categóricas (hasta 1000 categorías diferentes)
3. Variables agrupadas (cuando existen demasiadas categorías pueden agruparse en subcategorías)
4. Variables mixtas (variables que contienen valores numéricos y categóricos a la vez)
Crea una ventana con información estadística de cada variable, en la que se puede visualizar:
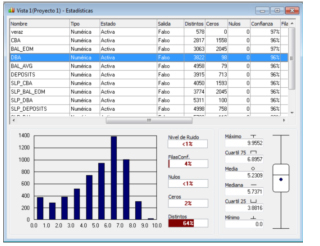
1. Mínimo
2. Máximo
3. Promedio
4. Mediana
5. Primer y tercer cuartil
6. Cantidad de Nulos, Ceros y Distintos
7. Gráfico de distribución
8. Diagrama de caja (box and whisker plot)
Prepara las variables en forma automática
Trata con nulos y valores extremos (outliers) en forma automática.
Descarta variables automáticamente por diferentes criterios configurables por el usuario
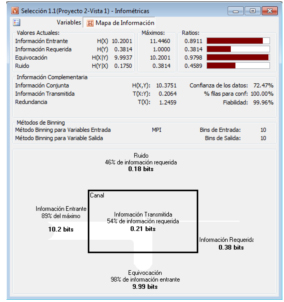
Trata con datos no balanceados en forma automática.
Mide la cantidad de información contenida en los datos
Crea un mapa de información con varias mediciones útiles:
La selección de variables se realiza midiendo la cantidad de información que aportan las variables en conjunto, logrando de esta manera, una selección óptima y con muy baja colinealidad.
No sólo la selección se realiza en forma automática, sino también la cantidad de variables a seleccionar se calcula automáticamente midiendo la probabilidad de que la información contenida en las variables de la muestra de desarrollo es representativa de la información que se encontraría en la población.
Modelos óptimos y simples de entender
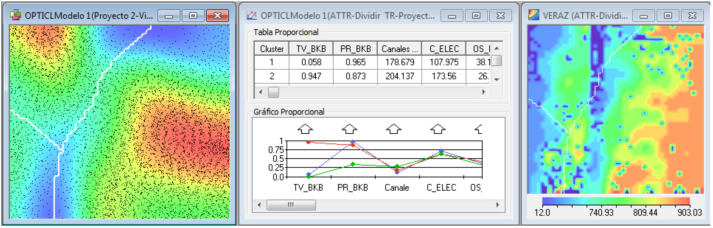
Distintas mediciones de rendimiento de los modelos de predicción y scoring: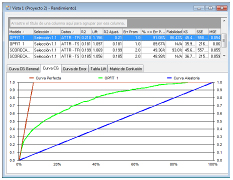
Es posible visualizar múltiples modelos para su comparación
Tanto la interface visual como la Ayuda pueden ser configurados para
Trabajar en Español como en Inglés.
Demostración on-line de Powerhouse™
Demostración en 3 minutos de Powerhouse™ (en inglés)
Requerimientos
Sistema Operativo: Windows 7, XP, Vista, NT, 98
128 Mb RAM mínimo
100 Mb en disco disponible
Powerhouse carga los datos en memoria lo que le permite ejecutar los algoritmos en forma rápida y eficiente.Carga los datos directamente en formato texto o a través de ODBC en cualquier formato.
Trabaja con datos hasta 10.000 variables y sin límites en la cantidad de filas.
Separa los datos en forma automática en Desarrollo (Training Set) y Prueba (Test Set).
Los datos de prueba son utilizados solamente para evaluar el modelo a pedido del usuario ya que el modelo es desarrollado enteramente con los datos de desarrollo.
Genera y carga una especificación de los datos si es necesario (metadata)
Definición de Nulos (por ejemplo, se puede definir que un nulo es un vacío o un label cualquiera)
Reemplazo automático de Nulos tanto en datos de desarrollo como en datos de prueba, en forma separada
Trabaja con variables de distintos tipos:
1. Variables numéricas (números enteros o decimales)
2. Variables categóricas (hasta 1000 categorías diferentes)
3. Variables agrupadas (cuando existen demasiadas categorías pueden agruparse en subcategorías)
4. Variables mixtas (variables que contienen valores numéricos y categóricos a la vez)
Crea una ventana con información estadística de cada variable, en la que se puede visualizar:
1. Mínimo
2. Máximo
3. Promedio
4. Mediana
5. Primer y tercer cuartil
6. Cantidad de Nulos, Ceros y Distintos
7. Gráfico de distribución
8. Diagrama de caja (box and whisker plot)
Prepara las variables en forma automática
Trata con nulos y valores extremos (outliers) en forma automática.
Descarta variables automáticamente por diferentes criterios configurables por el usuario
- Demasiados Nulos
- Demasiada cantidad de ceros
- Demasiado ruido
- Poca confiabilidad de representatividad de la población
- Un solo valor (constante)
- Igual rango
- Igual Entropía
- Mínima Pérdida de Información (método supervisado)
- Mayor Señal (Signa-to-Noise Ratio)
Trata con datos no balanceados en forma automática.
Mide la cantidad de información contenida en los datos
Crea un mapa de información con varias mediciones útiles:
- Información requerida para realizar el modelo
- Información disponible en las variables independientes
- Información útil para realizar el modelo
- Cantidad de ruido presente en los datos
- Información redundante
- Confianza de representatividad de los datos
La selección de variables se realiza midiendo la cantidad de información que aportan las variables en conjunto, logrando de esta manera, una selección óptima y con muy baja colinealidad.
No sólo la selección se realiza en forma automática, sino también la cantidad de variables a seleccionar se calcula automáticamente midiendo la probabilidad de que la información contenida en las variables de la muestra de desarrollo es representativa de la información que se encontraría en la población.
Modelos óptimos y simples de entender
- OPFIT es un modelo de predicción y scoring que realiza un mapa no lineal entre la información que contienen las variables independientes y la variable a predecir
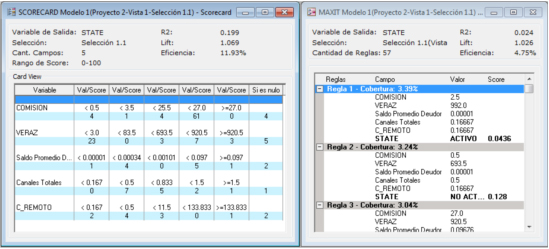
- Scorecard es un modelo de predicción y scoring que provee una representación intuitiva y simple de entender de las relaciones encontradas en los datos.
- MAXIT es un modelo en el que el mapa de información se realiza mediante reglas
- OPTICL es un modelo de clustering para ser usado tanto en análisis explicatorio como en aplicaciones de segmentación. Varias herramientas visuales acompañan el modelo para su exploración:
- Espectro: brinda una visión general de cómo están distribuidas las variables en los clusters
- Comparación de clusters: información más detallada sobre cada variable y su distribución en los clusters
- Mapas de Calor: la distribución de los valores de cada variable se visualiza mediante mapas de calor
Distintas mediciones de rendimiento de los modelos de predicción y scoring:
- Curva de error
- Curva Lift acumulada
- Curva Lift general
- Table Lift
- Matriz de confusión
- Gráfico de dispersión
Es posible visualizar múltiples modelos para su comparación
Tanto la interface visual como la Ayuda pueden ser configurados para
Trabajar en Español como en Inglés.
Demostración on-line de Powerhouse™
Demostración en 3 minutos de Powerhouse™ (en inglés)
Requerimientos
Sistema Operativo: Windows 7, XP, Vista, NT, 98
128 Mb RAM mínimo
100 Mb en disco disponible